
日志收集架构
将程序日志存储到文件中并不能很好地解决查看问题,尤其对于互联网应用,开发运维人员需要打开巨大的日志文件,在海量的日志中寻找他们需要的那一点点内容,犹如大海捞针。因为在日志文件中有需要关注的内容,也有大量并不需要关注的内容,怎样以可视化的方式,简单快速地查找到关注的内容,这就是日志收集设计需要解决的问题。
系统希望实现以下4个目标。
(1) 具有海量存储能力:能够存储海量数据,并且保证数据可靠性(不丢失)和检索能力。
(2) 具有全文检索能力:能够像百度一样搜索某个关键词就找到对应的内容。
(3) 具有链路追踪能力:能够一次性查询到单笔交易中的所有日志。
(4) 具有统计分析能力:可以根据各种指标进行汇总查询。
海量存储能力和全文检索能力很容易实现,只要选用支持海量存储,并且具有全文检索能力的数据库引擎即可,目前主流采用的就是
Elasticsearch数据库。
链路追踪能力可以参见3.10节,只需要在日志中记录TraceID和SpanID就可以达到目的。统计分析能力是最难的,因为这是关系型数据库的特长,并不是搜索引擎数据库做不到,但前提是必须先将数据结构化。下面将详细阐述日志收集的设计思路。
6.8.1 日志收集架构的设计
日志收集流程如图6-23所示,几乎所有的日志收集架构都可以抽象为4个步骤:日志采集、日志清洗、日志存储和日志分析。
(1) 日志采集:可以从不同的数据源采集日志,可以是应用程序、数据库、中间件、网络、操作系统等。
(2) 日志清洗:将采集到的日志进行清洗、过滤、分析,转化为结构化的数据形式。
(3) 日志存储:将清洗后已经结构化的数据存储到存储引擎中。
(4) 日志分析:通过存储引擎对日志进行可视化的查询和统计分析。

图6-23 日志收集流程
日志收集架构设计如图6-24所示,日志采集程序要能够从不同的软件、设备、操作系统中主动采集日志,而不是由各个程序主动上送日志。例如,可以收集MySQL、Oracle等不同数据库的日志, Nginx、
Tomcat等不同Web服务器的日志,等等。
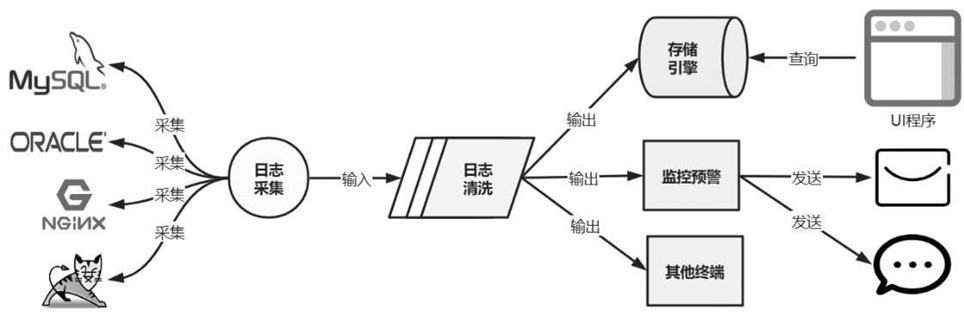
图6-24 日志收集架构设计
由于采集的日志来源不同,因此日志输出的格式也各不相同,大多数只是纯文本内容的流式输出。因此,这些日志需要输入日志清洗程序中进行解析和转换。日志清洗程序按照过滤器进行设计,一条日志经过层层清洗和转化,最终得到便于查询和分析的结构化数据。例如,将日志转化为JSON结构、XML结构等。
例如,有“name yinhongliang age 20 sex man”这样一行日志,处理过程如下。
第一层过滤先按照空格切割为长度为6的数组,即
[name,yinhongliang,age,20,sex,man]。
第二层过滤对数组中的元素进行两两组合,就可以将其解析为
{"name":"yinhongliang", "age":20,"birthday":"", sex:"man"} 这样一条结构化的JSON数据。
经过清洗后的结构化数据就可以输出到存储引擎中存储了。例
如,输出到MongoDB、MySQL、Elasticsearch中,甚至可以输出到控制台、磁盘文件、网络监听服务等地方。其中最常用的就是输出到数据库中。这样就可以开发程序来查询数据库中的数据,从而完成对于日志的查询和统计分析能力。由于所有的日志都会经过日志清洗程序,所以可以通过监测是否存在指定的错误日志,来达到监控预警的目的。
以下是3个经常使用的场景案例,如图6-25所示。
(1) 对于MySQL可以监控它的慢日志(默认为slow.log),当发现慢SQL时,发送邮件通知开发人员,存在SQL语句需要优化,不需要开发人员自己去排查问题。
(2) 对于Nginx可以监控它的错误日志(默认为error.log),当发现被代理的Upstream节点(上游节点)不通时,可以立即通知运维人员,服务可能存在宕机。
(3) 对于Tomcat服务可以监控它的控制台日志(默认为
catalina.out),当发现Out of memory这样的关键词时,就发送通知给运维人员,提醒程序内存溢出。
同理,可以监控各种设备和软件,对比日志中的关键词,从而达到个性化的监控预警目的。
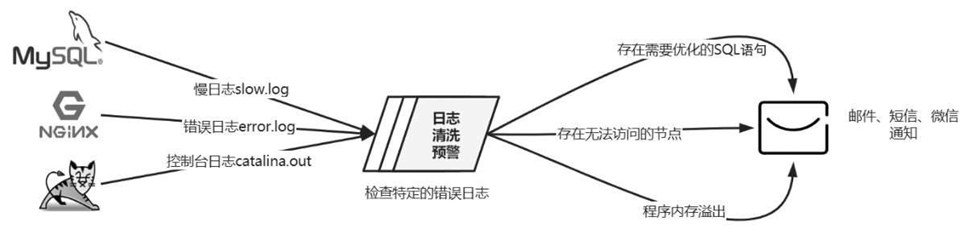
图6-25 日志监控预警案例
6.8.2 Elastic Stack架构组件介绍
当前主流的开源日志收集与分析架构之一就是ELastic Stack架构。
ELastic Stack以前称为ELK Stack,其中E是指Elasticsearch,L是指
Logstash,K是指Kibana,使用这3个组件可以构建一套完整的日志采集、清洗、存储和分析的平台。
(1) Elasticsearch:分布式搜索和分析引擎,主要用于结构化的日志存储和查询分析。
(2) Logstash:用户日志清洗,将非结构化的流式日志转化为结构化日志。
(3) Kibana:提供可视化的日志查询和统计分析、权限管理等。
ELK Stack日志收集架构如图6-26所示。Elasticsearch的作用是进行结构化的日志存储。Logstash的作用是日志采集和清洗,将非结构化的流式日志转化为结构化日志。Kibana提供可视化的日志查询和统计分析。开发人员直接使用Kibana进行日志查询,而不再需要接触服务器日志文件,只需要分配Kibana的系统账号即可,从而还可以控制不同的人员可查看的日志范围。
随着ELK的发展,又有新成员Beats的加入,所以就形成了ELastic Stack。
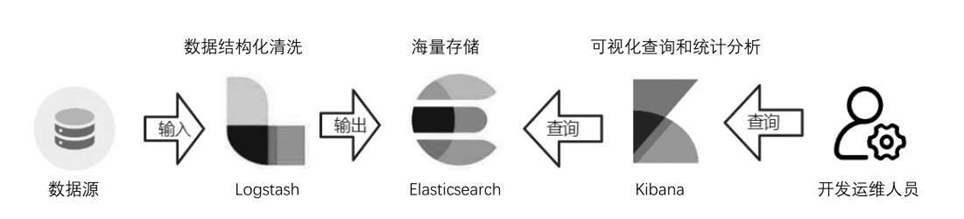
图6-26 ELK Stack日志收集架构
1. Elasticsear ch Elasticsearch在日志收集中的作用是存储结构化的日志数据,用于查询和分析,以下内容引用自百度百科。
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口。Elasticsearch
是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在
Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎。
2. Logstash
Logstash是一个开源实时的管道式日志收集引擎,可以动态地将不同来源的数据进行归一,并且将格式化的数据存储到所选择的位置。
Logstash流水线原理如图6-27所示。Logstash包含3个组件,分别是输入组件(INPUTS)、输出组件(OUTPUTS)和过滤器组件
(FILTERS)。其中输入组件和输出组件是必选组件。输入组件的目的
是从不同的数据源接收日志数据,经过过滤器组件进行过滤清洗和结构转换,最后经过输出组件进行输出,可以直接输出到Elasticsearch数据库中。如果不使用过滤器组件,则接收数据后直接输出到存储引擎中。
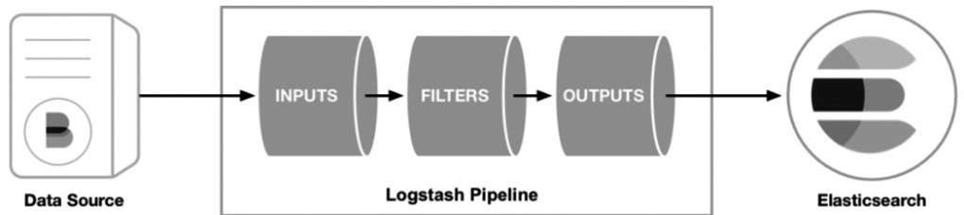
图6-27 Logstash流水线原理
Logstash输入输出设计如图6-28所示。Logstash提供了50多种输入组件、50多种输出组件、40多种过滤器组件,可以从诸如文件、数据库、Web应用、操作系统、网络、防火墙、消息队列等多种数据源输入数据;也可以将数据输出到文件、数据库、控制台、操作系统、网络、消息队列等终端中,几乎涵盖了所有需要的业务场景。
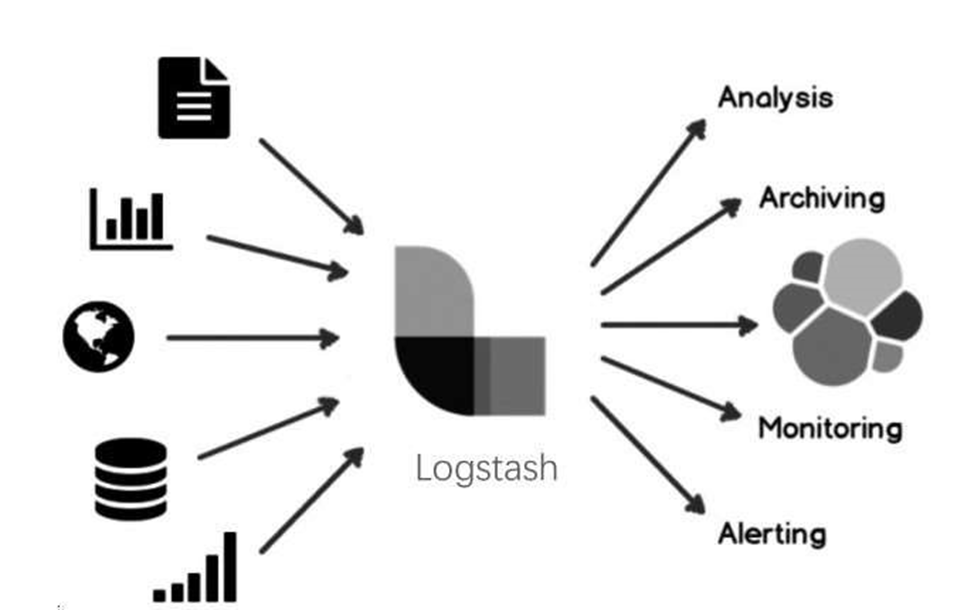
图6-28 Logstash输入输出设计
3. Kibana
Kibana是一个十分强大的可视化工具,可以使用柱状图、线状图、饼图、热力图等形式按照不同维度统计日志信息,也可以自己定制化各种仪表盘,如图6-29所示。
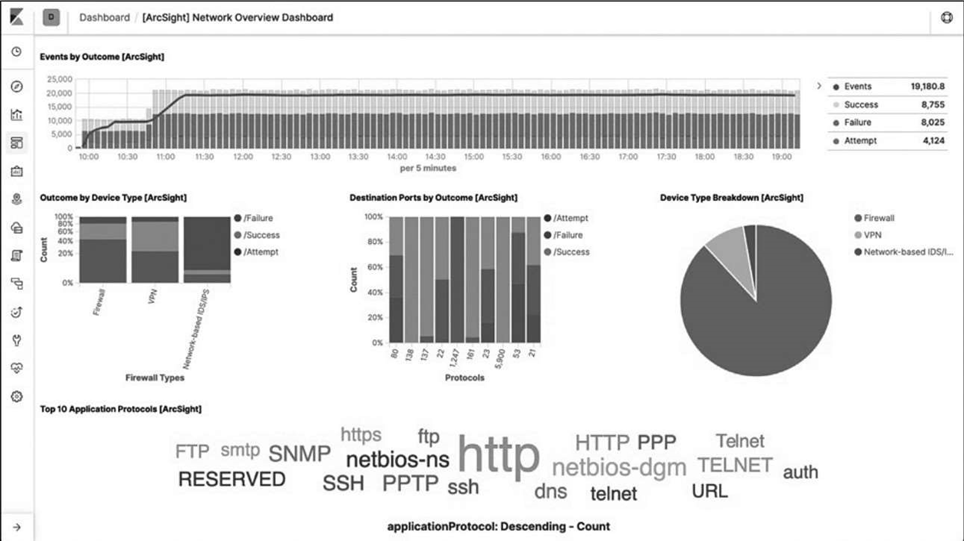
图6-29 Kibana界面
开发人员不需要再去各个服务器、各个文件中查看日志文件,而是直接通过Kibana查询Elasticsearch中的数据即可,可视化的界面操
作,统一的权限管理,能够极大地提高开发和运维的效率,Kibana查询界面如图6-30所示。
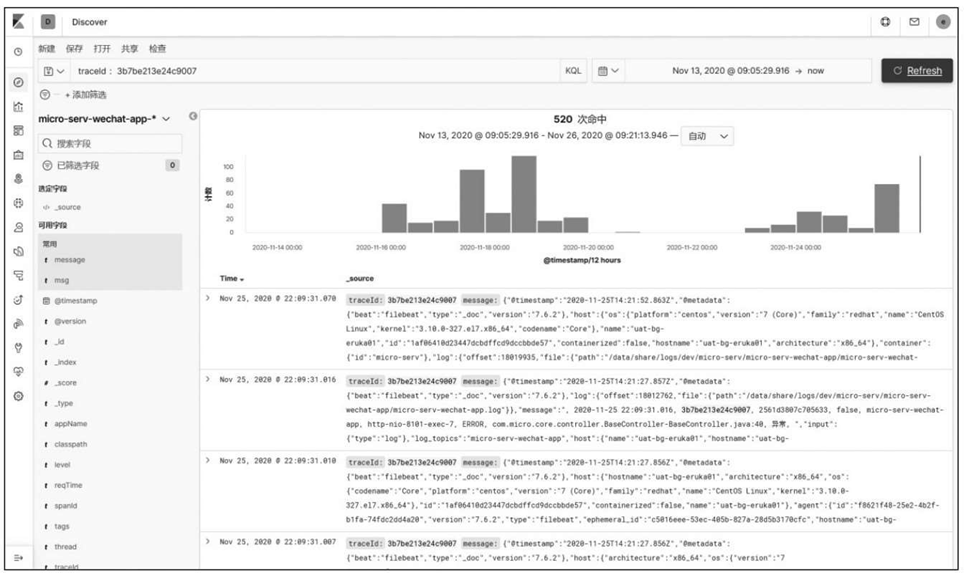
图6-30 Kibana查询界面
4. Beats
Beats是一个日志采集工具,可以将采集的日志直接输出到
Elasticsearch中,也可以输出到Logstash中,可以极大地简化日志采集的过程(否则每个数据源都要主动推送数据到Logstash中),如图6-31所示。
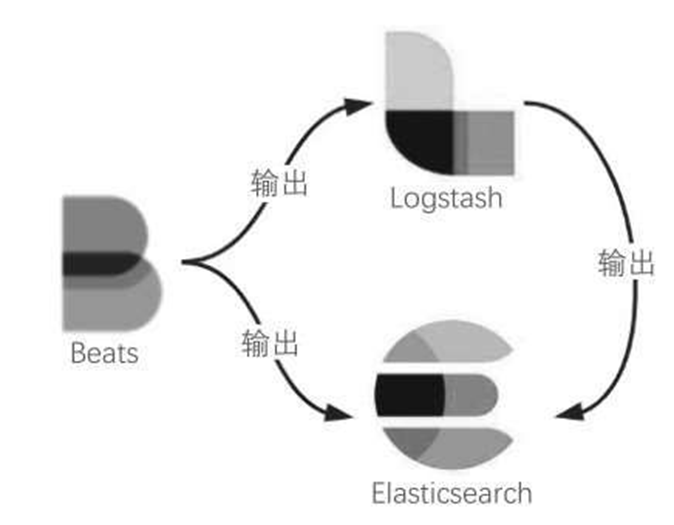
图6-31 Beats使用
Beats包含6种工具,具体如下。
(1) Filebeat:轻量型日志采集器,可以从安全设备、云、容器、主机进行数据收集。采集的来源为文件,可以通过tail -f实时读取日志变化,将其输出到Logstash或Elasticsearch中。
(2) Packetbeat:轻量型网络数据采集器,可用于监测HTTP 等网络协议,随时掌握应用程序延迟和错误、响应时间、流量、SLA性能、用户访问量和趋势等。
(3) Metricbeat:轻量型指标采集器,用于从系统和服务中收集指标。将Metricbeat部署到Linux、Windows和Mac主机,Metricbeat 就能够以一种轻量型的方式输送各种统计数据,如系统级的CPU使用率、内存、文件系统、磁盘 I/O和网络I/O统计数据等。
(4) Winlogbeat:轻量型Windows事件日志采集器,用于密切监控基于Windows的基础设施上发生的事件。可以将Windows事件日志流式传输至Elasticsearch和Logstash。
(5) Auditbeat:轻量型审计日志采集器,可以收集Linux审计框架的数据,监控文件完整性。可监控用户的行为和系统进程,分析用户事件数据。Auditbeat与Linux审计框架直接通信,收集与Auditd相同的数据,并实时发送这些事件消息到Elastic Stack。
(6) Heartbeat:面向运行状态监测的轻量型采集器,通过主动探测来监测服务的可用性。通过给定URL列表,通过心跳机制询问系统是否运行正常。
6.8.3 Elastic Stack架构模式
对于不同的应用场景,可以采用不同的Elastic Stack架构模式进行日志收集。
1. 3种无Filebeat 架构
如图6-32所示,如果应用日志可以结构化为JSON结构,则可以直接将结构化数据存储到Elasticsearch中,借助Kibana从Elasticsearch中进行查询。这样的架构模式最简单,节省了Logstash的过滤和传输流程,可以极大地提高日志采集的性能,适用于日志量较小的小型项目。
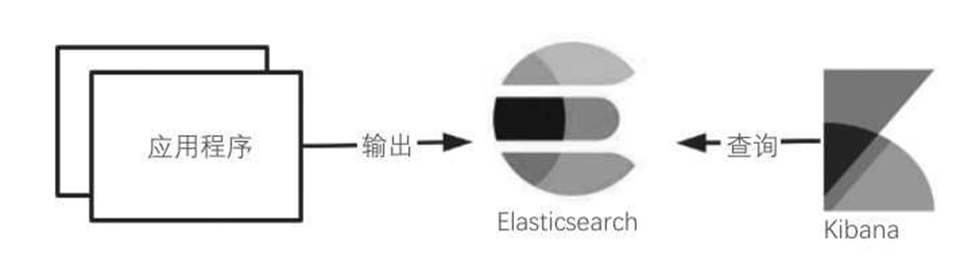
图6-32 Elastic Stack架构模式(1)
如图6-33所示,如果日志数据无法结构化,则可以将非结构化的日志直接输入Logstash中,在Logstash中进行格式化处理,形成JSON结构,再存储到Elasticsearch中,最后借助Kibana进行查询。这样的架构模式适用于大多数的中型项目。

图6-33 Elastic Stack架构模式(2)
如图6-34所示,为了防止Logstash的压力过大,可以借助Kafka这种高吞吐量的消息队列,将日志直接输出到Kafka中,再输入Logstash 中,在Logstash中进行格式化处理,形成JSON结构,再存储到
Elasticsearch中,最后借助Kibana进行查询。这样的架构模式适用于日志量较大的集群和分布式项目。

图6-34 Elastic Stack架构模式(3)
2. 3种有Filebeat 架构
以上3种架构对程序都具有一定的侵入性,应用程序必须主动输出日志。如果只是想上线一套日志收集系统,而不想改变任何原有程序,就可以如图6-35所示,使用Filebeat主动监控应用程序的日志文件。Filebeat可以将日志文件中的内容直接输出到Elasticsearch、
Logstash或Kafka中,因此在前3种架构之前加入Filebeat,就可以形成3 种新的架构模式。
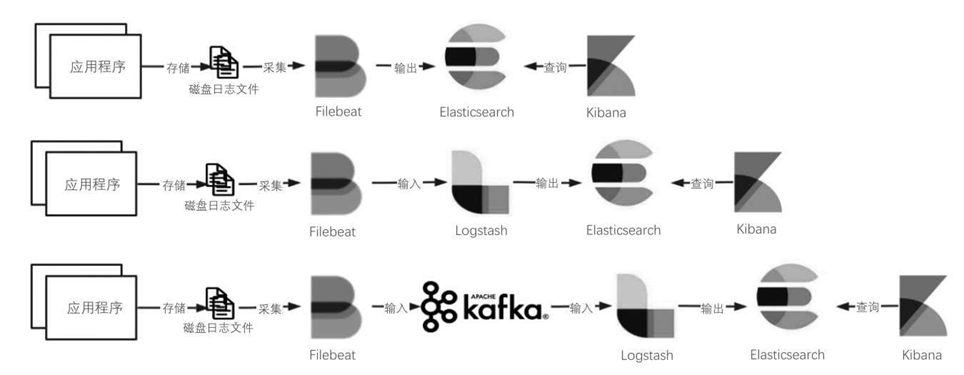
图6-35 Elastic Stack架构模式(4)
Filebeat有以下两种部署方式。
第一种部署方式如图6-36所示,将Filebeat应用与每个应用部署在一起,作为一个代理服务去采集日志,然后再输出到Logstash中。这种部署方式的优点是多个Filebeat服务之间互不影响,采集性能较好,但是部署相对麻烦;缺点是由于Filebeat需要实时监控和采集日志,对资源也会有一定的损耗,尤其是当日志量变化较快时,这样就会抢占服务器资源,影响应用程序运行。
第二种部署方式如图6-37所示,将所有的日志通过NFS共享存储在一起,然后部署一台或多台独立的Filebeat服务器。这种部署方式的优点是可以独立部署Filebeat服务,与应用程序分离,即使Filebeat对资源消耗较大,也不会影响到业务应用的运行。
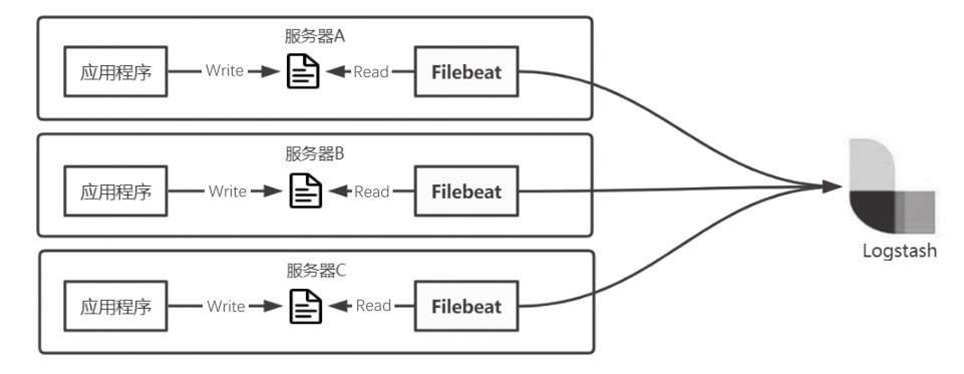
图6-36 Filebeat部署方式(1)
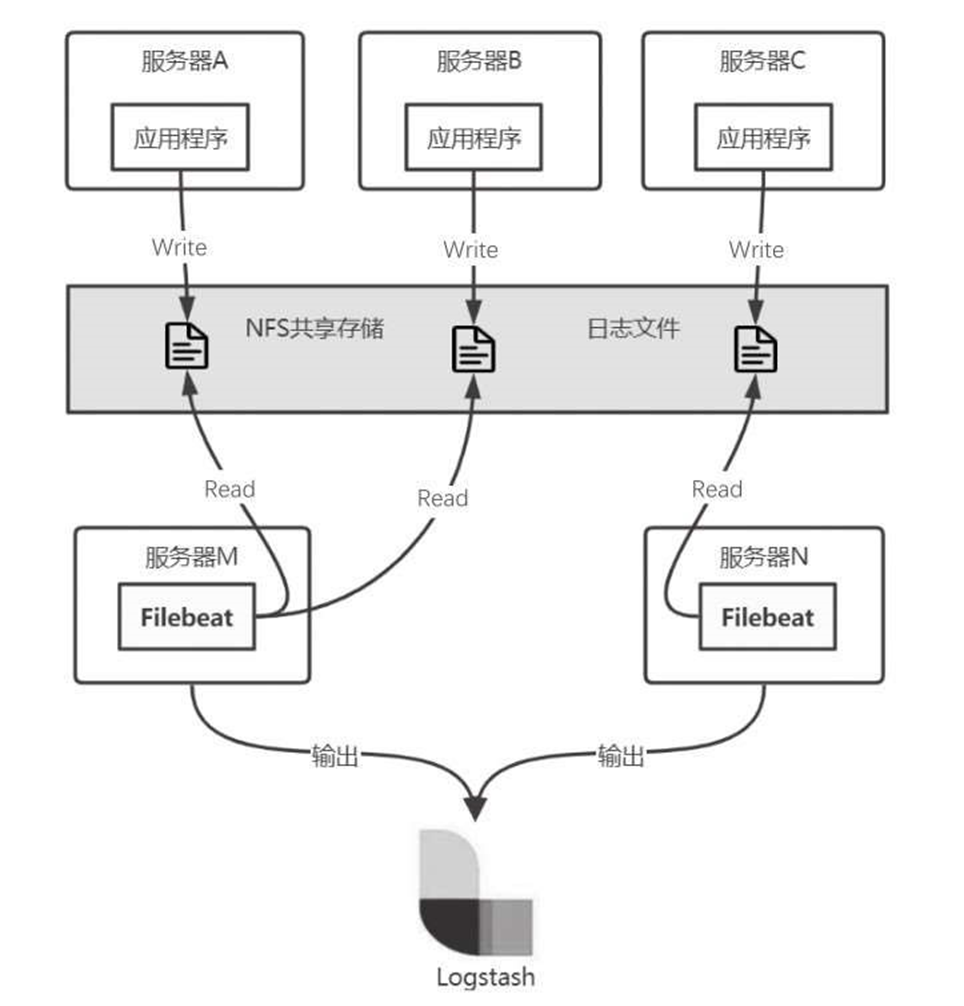
图6-37 Filebeat部署方式(2)