
程序日志设计
程序日志是最为详细的日志,最常见的方式就是输出到文件和控制台。如果通过查询接口日志无法判断问题,那么最直接的手段就是分析程序日志。然而,程序日志的数据量过于庞大,对日志的查看和分析也带来了巨大的挑战。
1.日志级别的划分和设定
程序日志一定要设定日志级别。日志级别通常从低到高分为8种,分别是ALL、TRACE、DEBUG、INFO、WARN、ERROR、FATAL和
OFF。
(1) ALL:即所有,显示所有级别的日志。
(2) TRACE:即追踪,打印程序的运行轨迹,比DEBUG的粒度更细。
(3) DEBUG:即调试,程序运行的事件明细信息,是调试程序时使用最多的日志级别。
(4) INFO:即信息,较粗的粒度描述程序的运行过程,通常为开发人员主动输出的提示性信息。
(5) WARN:即警告,提示可能存在潜在危险的信息。
(6) ERROR:即错误,明确的错误信息,但是程序可以正常执行。
(7) FATAL:即致命,极其严重的错误,可能会导致程序终止或崩溃。
(8) OFF:即关闭,不显示任何日志。
不同的日志级别输出的内容范围不同,具有一定的包含关系,如表6-12所示。
表6-12 日志级别的包含关系
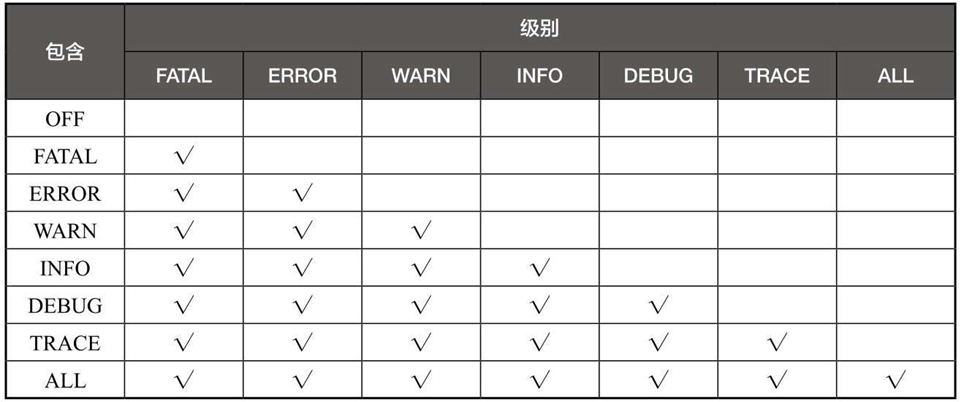 其中ERROR、WARN、INFO和DEBUG是最常使用的日志级别。
其中ERROR、WARN、INFO和DEBUG是最常使用的日志级别。
2.如何有效地输出程序日志
(1) 日志输出对于程序的性能是有比较严重影响的,所以在开发阶段增加的非必要性日志输出语句应该在上线前全部删除。在程序优化时,只是删除了一些无关紧要的日志输出,就可能提高十余倍的接口吞吐量,所以不要小看这个问题。
(2) 在开发和测试环境中使用较低的日志级别,而在生产环境中使用较高的日志级别。例如,一般在开发和测试环境中使用DEBUG级别,而在生产环境中使用WARN或ERROR级别。
(3) 在上线初期使用较低的日志级别,如DEBUG级别,避免在上线初期程序不稳定,便于快速查证问题。待程序稳定后,修改到较高的日志级别,如ERROR级别,减少日志的输出。(4)对于SQL语句的日志输出,大多数定义在DEBUG级别。由于 90%的问题都需要排查SQL的执行是否正确,因此除非确保程序十分稳定,一般可以不关闭SQL日志,以便于快速查证问题。
3.程序日志的输出方式程序日志的输出主要分为同步输出和异步输出两种方式。
(1) 同步输出日志:可以保持日志输出顺序与程序执行、用户操作顺序一致,但是对于异步执行的程序,日志依然无法保证其顺序性。同步输出日志会占用程序运行时间,造成用户响应时间加长。
(2) 异步输出日志:可以加快程序响应速度,但是日志顺序性被破坏,不便于排查问题。
4.通用程序日志存储设计
由于程序日志量较大,如果将所有日志都写入一个文件中,就会导致文件过大,打开文件都会存在问题,查看日志就变得更加困难,因此通用日志文件存储设计如下。
(1) 按照日期滚动存储。每日生成一个日志文件,保留固定的天数。这样可以保持数据只保留最近N天的文件。例如,只保留最近30天的日志,则第31天的日志会覆盖第1个日志文件,滚动存储。日志文件名通常为xxxx.log.xxxx-xx-xx,如xxx.log.2020-12-30、xxx.log.2020-12-
31。
(2) 按照文件大小滚动存储。设定单个文件的大小,如一个日志文件最大为500MB,超过500MB则生成新文件,再设定最大保留的文件个数如100个,则第101个文件会覆盖最初的日志文件,滚动存储。
日志文件名通常为xxx.log.sequnce_num,如xxx.log.1、xxxlog.2。(3)先按照日期,再按照文件大小滚动存储。这种方式结合了以上两种方法的优势,也是设计中推荐的方式。每天按照日期生成日志文件夹,然后在文件夹下存放当天的日志文件。当单个日志文件大小超过限定时,则按照序号生成日志。最终形成的日志为xxx.log.xxxxxx-xx.seqnum形式,如xxx.log.2020-12-30.1、xxx.log.2020-12-30.2。
(4) 存放实时日志。一般会在程序日志中存放一个最新的无后缀日志,用来保留当前的实时日志。日志文件名为xxx.log。
(5) 独立存放错误日志。为了更快速地排查问题,也可以将错误日志拆分出去,对于所有的程序异常单独形成日志。日志文件名为 xxx_error.log。
结合上述设计思路,可以得到一个分层滚动日志文件存储结构,清晰直观,便于查看,存储结构如图6-13所示。

图6-13 日志文件存储设计
5.按照业务属性做个性化的日志存储对于一些企业内部的管理系统,用户数量有限,并且人员按照组织机构、岗位进行了明确的划分,这时就可以依靠这种结构建立直达用户的日志文件结构,做到一个用户对应一个日志文件。
如图6-14所示,可以按照日期、分公司/部门/岗位等维度建立文件夹,然后在文件夹下按照员工的编号生成日志,这样可以保证每个员工每天生成一个独立的日志文件。当某个员工反馈系统问题时,就可以直接找到该员工的日志文件进行排查。
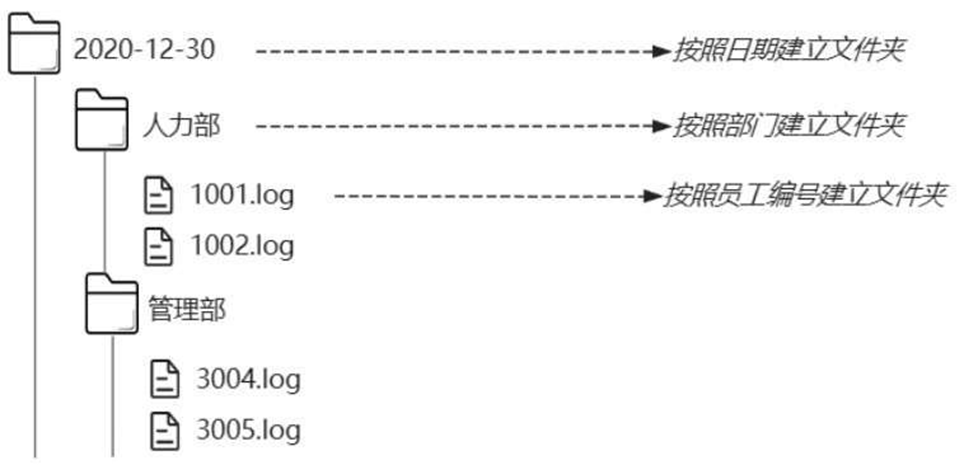
图6-14 按照组织结构人员存储日志设计
只要记住程序日志的宗旨是完整记录程序的执行过程,应当结合系统和业务特点,设计出便于查证问题的日志存储结构即可。
6.分布式架构下的日志存储
通常将日志存放在程序运行的项目服务器上,对于独立的单体服务还是比较容易查看的,因为文件位置固定,甚至只有一个日志文
件。但是,对于集群架构和分布式架构(图6-15),可能有几个、几十个,甚至上百个服务,每个服务都输出日志到自己的服务器上,当要排查问题时,就需要登录到不同的服务器上获取文件。有时开发或运维人员并不知道哪个日志文件能够定位问题,可能要将所有的日志文件查看一遍,这是十分不方便的。
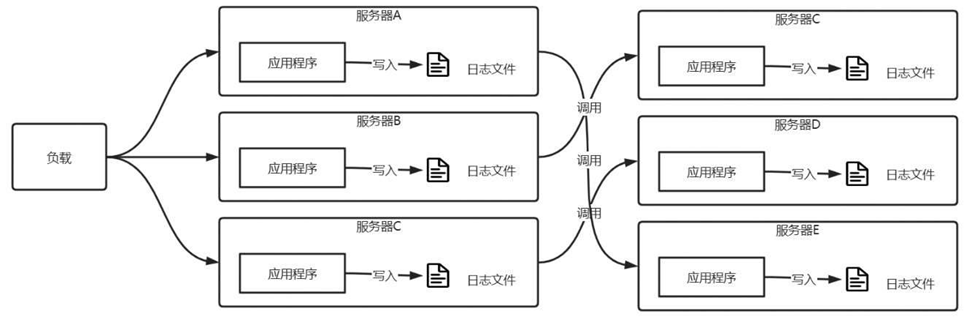
图6-15 负载和分布式架构下的日志存储
如图6-16所示,可以利用NFS共享存储来存储日志文件。在各应用服务器上挂载相同的存储目录,各应用均将自己的日志文件写入共享目录中。不同的应用采用不同的文件名进行区分即可。
运维或开发人员登录任意一台服务器,就可以在共享目录中查看到所有服务的日志文件,可极大地提高工作效率。当磁盘空间不足时,只需要扩展共享存储的磁盘空间即可。
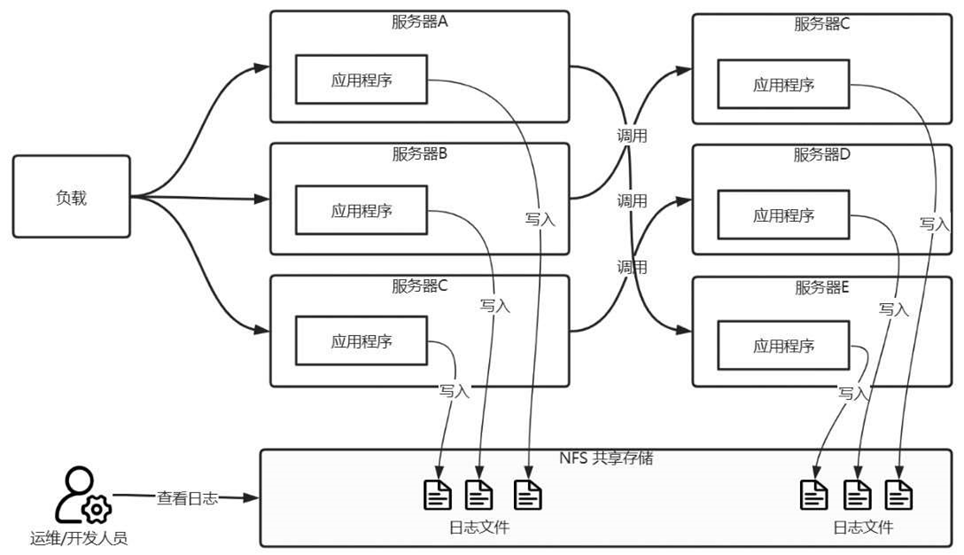
图6-16 NFS共享存储
任何架构设计都是有利有弊的,需要进行不同程度的权衡,因此需要注意以下事项。
(1) 使用NFS由于涉及网络传输,因此势必对日志的写入速度造成影响,但是因为在内网中使用,所以对性能影响并不大。
(2) 对于各个应用服务器一定要确保服务器重启时自动挂载共享存储,如果忘记挂载,则会造成日志文件直接输出到本地,不但容易造成磁盘爆满,而且后续再挂载共享存储时需要做很多的额外操作。
(3) 要对NFS共享服务搭建高可用,并且做好服务监控,否则一旦共享存储故障,就会导致关联服务全部故障。
无论是采用集群架构,还是采用分布式架构,都会将应用进行水平扩展,这样相同的应用就会部署到多个服务器上,即使用共享存储,查看起来依然不方便。水平扩展下将日志输出到不同文件中,如图6-17所示,订单服务水平部署3个服务,它们各自输出日志到共享存储中,当需要排查某一笔订单数据时,就要去3个日志文件中搜索,效率较低。
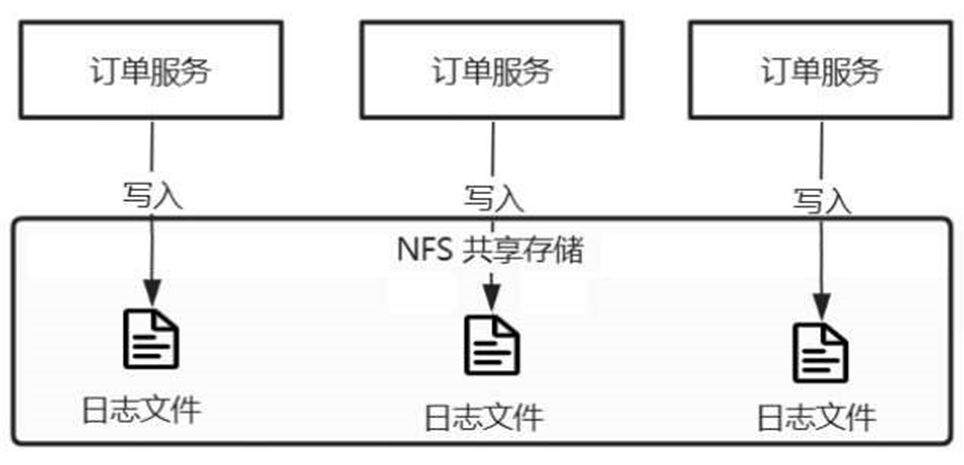
图6-17 水平扩展下输出到不同文件
如图6-18所示,可以利用NFS共享存储,将相同应用的日志全部写入同一个文件中,此时需要排查问题时只需要查看一个文件即可。
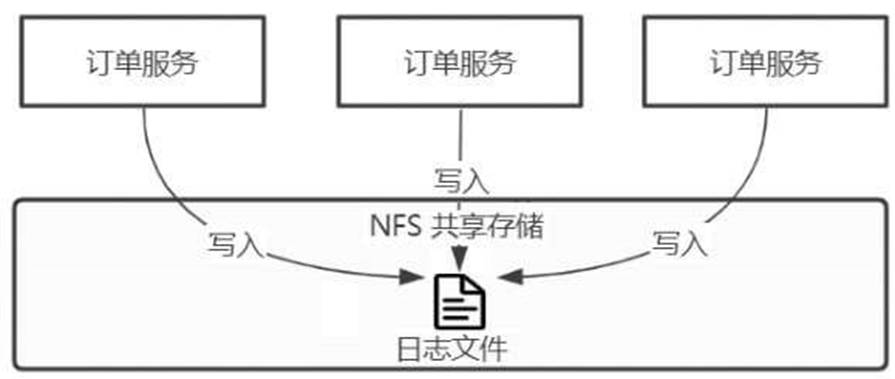
图6-18 水平扩展下输出到同一文件
由于文件属于共享资源,多个应用写入时会进行资源加锁和释放,因此不用担心文件的内容会彼此覆盖。但是,对于同一个共享文件的写入势必会造成资源的相互争抢,对日志的写入性能会有较大影响。
不存在绝对完美的架构,有优点就会有缺点,这就是架构师应该权衡之处。